Este texto é uma tradução livre para o Português, publicada pela Lavits em primeira-mão, do texto “The Nooscope Manifested: AI as Instrument of Knowledge Extractivism” de Matteo Pasquinelli e Vladan Joler.
*Matteo Pasquinelli e Vladan Joler
*Para citação: Matteo Pasquinelli e Vladan Joler, “O manifesto Nooscópio: Inteligência Artificial como Instrumento de Extrativismo do Conhecimento”, [Trad. Leandro Módolo & Thais Pimentel] KIM research group (Karlsruhe University of Arts and Design) e Share Lab (Novi Sad), 1 de Maio de 2020. Fonte: https://nooscope.ai
Acesse o Diagrama de erros, viéses e limitações do aprendizado de máquina completo aqui.
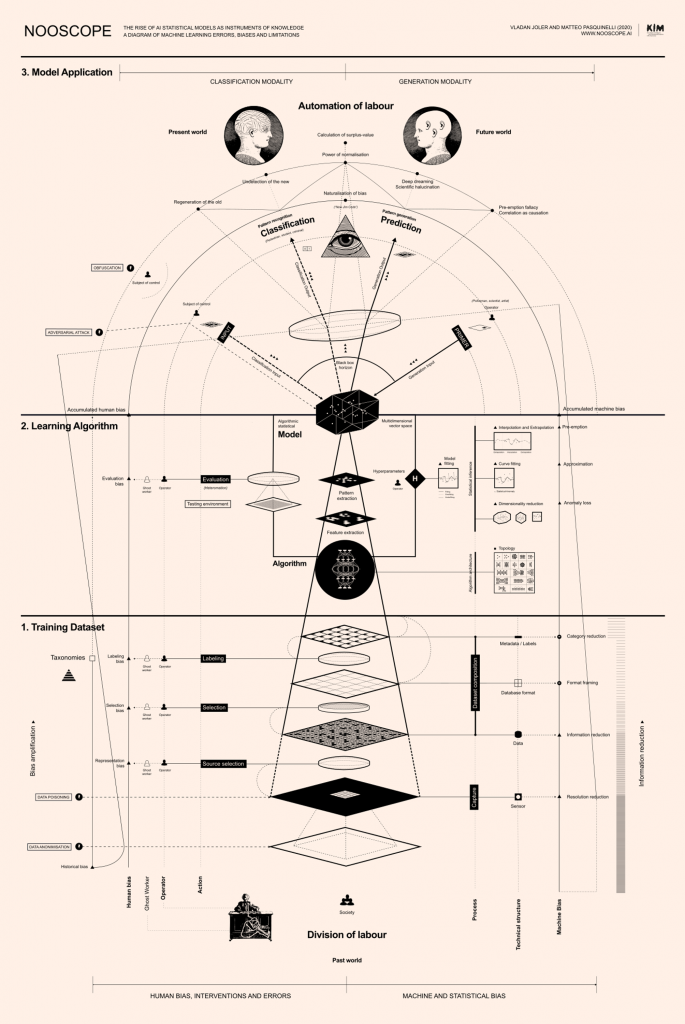
O Nooscópio é uma cartografia dos limites da inteligência artificial (IA), destinado a provocar a ciência da computação e as humanidades. Qualquer mapa é uma perspectiva parcial, uma maneira de provocar debates. Da mesma forma, este mapa é um manifesto – um manifesto de dissidentes da IA. Seu principal objetivo é desafiar as mistificações sobre inteligência artificial. Primeiramente quanto a definição técnica de inteligência e, em segundo, quanto a forma política de sua dita autonomia frente à sociedade e ao humano.1 Na expressão “inteligência artificial”, o adjetivo “artificial” carrega o mito da autonomia da tecnologia: sugere “mentes alienígenas”[1] caricaturais que se auto-reproduzem in sílico, mas, na verdade, mistifica dois processos de alienação: a crescente autonomia geopolítica das empresas de alta tecnologia e a invisibilização da autonomia dos trabalhadores em todo o mundo. O projeto moderno de mecanizar a razão humana claramente se transformou, no séc. XXI, em um regime corporativo extrativista do conhecimento e um colonialismo epistêmico.2 Isso não é surpreendente, uma vez que os algoritmos de aprendizado de máquina [machine learning] são os mais poderosos para a compressão de informações.
O objetivo do mapa Nooscópio é secularizar a IA do seu status ideológico de ‘máquina inteligente’ para o de instrumento de conhecimento. Em vez de evocar lendas da cognição alienígena, é mais razoável considerar o aprendizado de máquina como um instrumento de ampliação do conhecimento que ajuda a perceber características, padrões e correlações através de vastos espaços de dados que estão além do alcance humano. Na história da ciência e da tecnologia isso não é nenhuma novidade: ele já foi perseguido por instrumentos ópticos ao longo das histórias da astronomia e da medicina.3 Na tradição da ciência, os algoritmos de aprendizado de máquina é apenas um Nooscópio, um instrumento para ver e navegar no espaço do conhecimento (do grego skopein “examinar, olhar” e noos “conhecimento”).
Tomando emprestada a idéia de Gottfried Wilhelm Leibniz, o diagrama Nooscópio aplica a analogia da mídia óptica à estrutura de todos os aparatos de aprendizado de máquina. Discutindo o poder de seu calculus ratiocinator e “números característicos” (a ideia de projetar uma linguagem universal numérica para codificar e resolver todos os problemas do raciocínio humano), Leibniz fez uma analogia com instrumentos de ampliação visual, como o microscópio e o telescópio. Ele escreveu: “Uma vez que os números característicos sejam estabelecidos para a maioria dos conceitos, a humanidade possuirá um novo instrumento que aumentará as capacidades da mente em uma extensão muito maior do que os instrumentos ópticos fortalecem os olhos e substituirá o microscópio e o telescópio, na medida em que a razão é superior à visão.”4 Embora o objetivo deste texto não seja reiterar a oposição entre culturas quantitativas e qualitativas, a crença de Leibniz não precisa ser seguida. Controvérsias não podem ser computadas conclusivamente. O aprendizado de máquinas não é a forma definitiva de inteligência.
Instrumentos de medição e percepção sempre vêm com distorções embutidas. Do mesmo modo que as lentes de microscópios e telescópios nunca são perfeitamente curvilíneas e lisas, as lentes lógicas do aprendizado de máquina incorporam falhas e inclinações. Entender o aprendizado de máquina e registrar seu impacto na sociedade é estudar o grau em que os dados sociais são difratados e distorcidos por essas lentes. Isso geralmente é conhecido como o debate sobre o viés (inclinações/predisposições) na IA, mas as implicações políticas da forma lógica do aprendizado de máquina são mais profundas. O aprendizado de máquina não está trazendo uma nova era das trevas, mas uma racionalidade difratada, na qual, como será mostrado, uma episteme de causalidade é substituída por uma de correlações automatizadas. Em geral, a IA é um novo regime de verdade, prova científica, normatividade social e racionalidade, que muitas vezes toma a forma de uma alucinação estatística. Este manifesto diagrama é outra maneira de dizer que a IA, o Rei da computação (uma fantasia patriarcal do conhecimento mecanizado, “algoritmo mestre” e alpha machine) está nu. Aqui, estamos espiando dentro de sua caixa preta.

Sobre a invenção de metáforas como instrumentos de ampliação do conhecimento. Tesauro, Il cannocchiale aristotelico [O telescópio aristotélico], frontispício da edição de 1670, Turim.
[1] N.T – Optamos traduzir “alien” por “alienígena(s)”, uma vez que no campo das ciências cognitivas (tal como John Searle, Daniel Dennett, David Chalmers e cia) a expressão é usual e se refere a qualquer “mente” não humana, seja ela maquínica, seja um animal, um ET ou zombie etc.
A história da IA é uma história de experimentos, falhas de máquinas, controvérsias acadêmicas, rivalidades épicas em torno de financiamento militar, popularmente conhecidas como “invernos da IA”.5 Embora a IA corporativa hoje descreva seu poder com a linguagem da “magia negra” e da “cognição sobre-humana”, as técnicas atuais ainda estão em estágio experimental.6 Ela está agora no mesmo estágio em que estava o motor a vapor quando foi inventado, antes que as leis da termodinâmica necessárias para explicar e controlar seu funcionamento interno fossem descobertas. Da mesma forma, hoje existem redes neurais eficientes para o reconhecimento de imagens, mas não existe uma teoria da aprendizagem para explicar porque elas funcionam tão bem e como elas falham tanto. Como qualquer invenção, o paradigma do aprendizado de máquina se consolidou lentamente, neste caso através do último meio século. Um algoritmo mestre não apareceu da noite para o dia. Ao contrário, houve uma construção gradual de um método de computação que ainda precisa encontrar uma linguagem comum. Manuais de aprendizado de máquina para estudantes, por exemplo, ainda não compartilham uma terminologia comum. Como esboçar, então, uma gramática crítica do aprendizado de máquina que pode ser concisa e acessível, sem participar do jogo paranóico de definir uma Inteligência Geral?
Como instrumento de conhecimento, o aprendizado de máquina é composto de um objeto a ser observado (conjuntos de dados de treinamento), um instrumento de observação (algoritmo de aprendizagem) e uma representação final (modelo estatístico). A montagem desses três elementos é proposta aqui como um diagrama espúrio e barroco de aprendizado de máquina, extravagantemente denominado Nooscópio.7 Seguindo a analogia da mídia ótica, o fluxo de informações do aprendizado de máquina é como um feixe de luz que é projetado pelos dados de treinamento, comprimido pelo algoritmo e difratado para o mundo pelas lentes do modelo estatístico.
O diagrama Nooscópio tem como objetivo ilustrar dois lados do aprendizado de máquina ao mesmo tempo: como ele funciona e como ele falha – enumerando seus principais componentes, bem como o amplo espectro de erros, limitações, aproximações, inclinações, falhas, falácias e vulnerabilidades que são nativas ao seu paradigma.8 Essa dupla operação enfatiza que a IA não é um paradigma monolítico de racionalidade, mas uma arquitetura espúria feita de técnicas e truques de adaptação. Além disso, os limites da IA não são simplesmente técnicos, mas são imbricados pelo viés humano. No diagrama do Nooscope, os componentes essenciais do aprendizado de máquina estão representados no centro, as intervenções e os vieses humanas à esquerda, e as limitações e os vieses técnicas à direita. As lentes ópticas simbolizam os vieses e aproximações que representam a compressão e distorção do fluxo de informações. O viés total do aprendizado de máquina é representado pela lente central do modelo estatístico através do qual a percepção do mundo é difratada.
As limitações da IA são geralmente percebidas hoje graças ao discurso sobre os vieses – a ampliação das discriminações de gênero, raça, habilidades e classe social por algoritmos. No aprendizado de máquina, é necessário distinguir entre viés histórico, viés do conjuntos de dados e viés algorítmico, os quais ocorrem em diferentes estágios do fluxo de informações.9 O viés histórico (ou visão de mundo) já é aparente na sociedade antes da intervenção tecnológica. No entanto, a naturalização desse viés, que é a silenciosa integração da desigualdade em uma tecnologia aparentemente neutra, é por si só prejudicial.10 Parafraseando Michelle Alexander, Ruha Benjamin chamou de New Jim Code: “o emprego de novas tecnologias que refletem e reproduzem as desigualdades existentes, mas que são promovidas e percebidas como mais objetivas ou progressistas do que os sistemas discriminatórios de uma época anterior”.11 O viés do conjunto de dados é introduzido através da preparação do treinamento de dados por operadores humanos. A parte mais delicada do processo é a rotulagem de dados, na qual taxonomias antigas e conservadoras podem causar uma visão distorcida do mundo, deturpando diversidades sociais e exacerbando hierarquias sociais (veja abaixo o caso do ImageNet).
Viés algorítmico (também conhecido como viés de máquina, viés estatístico ou viés de modelo, ao qual o diagrama Nooscópio dá atenção especial) é a ampliação adicional do viés histórico e viés do conjuntos de dados por algoritmos de aprendizado de máquina. O problema do viés se originou principalmente do fato de que os algoritmos de aprendizado de máquina estão entre os mais eficientes para a compressão de informações [data compression], o que engendra problemas de resolução, difração e perda de informações.12 Desde os tempos antigos, os algoritmos têm sido procedimentos de natureza econômica, projetados para alcançar um resultado com o menor número de etapas e com o consumo da menor quantidade de recursos: espaço, tempo, energia e trabalho.13 A corrida armamentista das empresas de IA ainda está preocupada em encontrar os algoritmos mais simples e rápidos com os quais capitalizar dados. Se a compressão de informações produz a taxa máxima de lucro na IA corporativa, do ponto de vista da sociedade, produz discriminação e perda de diversidade cultural.
Embora as consequências sociais da IA sejam popularmente entendidas sob a questão do viés, o entendimento comum das limitações técnicas é conhecido como o problema caixa preta. O efeito caixa preta é uma questão real de redes neurais profundas (que filtram tanto informações que sua cadeia de raciocínio não pode ser revertida), mas se tornou um pretexto genérico para a opinião de que os sistemas de IA não são apenas inescrutáveis e opacos, mas até “alienígenas” e fora de controle.14 O efeito caixa preta faz parte da natureza de qualquer máquina experimental no estágio inicial de desenvolvimento (já foi observado que o funcionamento do motor a vapor permaneceu um mistério por algum tempo, mesmo depois de ter sido testado com sucesso). O problema atual é a retórica da caixa preta, que está intimamente ligada a sentimentos conspirativos nos quais a IA figura como um poder oculto que não pode ser estudado, conhecido ou controlado politicamente.
A digitalização em massa, que se expandiu com a Internet nos anos 90 e aumentou com os centros de dados nos anos 2000, disponibilizou vastos recursos de dados que, pela primeira vez na história, são gratuitos e não regulamentados. Um regime de extrativismo do conhecimento (então conhecido como Big Data) gradualmente empregou algoritmos eficientes para extrair “inteligência” dessas fontes abertas de dados, principalmente com o objetivo de prever o comportamento do consumidor e vender anúncios. A economia do conhecimento se transformou em uma nova forma de capitalismo, chamada capitalismo cognitivo e, em seguida, capitalismo de vigilância, por diferentes autores.15 Foi a Internet que fez transbordar informações, enormes centros de dados, microprocessadores mais rápidos e algoritmos de compressão de dados lançando as bases para o surgimento dos monopólios em IA no século XXI.
Que tipo de objeto técnico e cultural é o conjunto de dados que constitui a fonte da IA? A qualidade dos dados de treinamento é o fator mais importante que afeta a chamada ‘inteligência’ que os algoritmos de aprendizado de máquina extraem. Há uma perspectiva importante a ser levada em consideração, a fim de entender a IA como um Nooscópio. Os dados são a primeira fonte de valor e inteligência. Algoritmos são os segundos; elas são as máquinas que computam esse valor e inteligência em um modelo. No entanto, os dados de treinamento nunca são brutos, independentes e imparciais (eles próprios já são ‘algorítmicos’).16 A criação, formatação e edição dos conjuntos de dados de treinamento é uma tarefa trabalhosa e delicada, provavelmente mais significativa para os resultados finais do que os parâmetros técnicos que controlam o algoritmo de aprendizado. O ato de selecionar uma fonte de dados em vez de outra é a marca profunda da intervenção humana no domínio das mentes “artificiais”.

O conjunto de dados de treinamento é uma construção cultural, não apenas técnica. Isso deralmente inclui dados de input associados ao output ideal do dados, como imagens com suas descrições, também chamadas de rótulos ou metadados.17 O exemplo canônico seria uma coleção de museu e seus arquivos, no qual as obras de arte são organizadas por metadados como autor, ano, meio etc. O processo semiótico de atribuir um nome ou uma categoria a uma imagem nunca é imparcial; essa ação deixa mais uma marca humana profunda no resultado final da cognição da máquina. Um conjunto de dados de treinamento para aprendizado de máquina geralmente é composto pelas seguintes etapas: 1) produção: trabalho ou fenômeno que produz informações; 2) captura: codificação das informações em um formato de dados por um instrumento; 3) formatação: organização dos dados em um conjunto de dados; 4) rotulagem: no aprendizado supervisionado, a classificação dos dados em categorias (metadados).
A inteligência da máquina é treinada em vastos conjuntos de dados que são acumulados de maneiras nem tecnicamente neutras nem socialmente imparciais. Os dados brutos não existem, pois dependem do trabalho humano, de dados pessoais e de comportamentos sociais que se acumulam por longos períodos, por meio de redes estendidas e taxonomias controversas.18 Os principais conjuntos de dados de treinamento para aprendizado de máquina (NMIST, ImageNet, Labeled Faces in the Wild etc.) tiveram origem em empresas, universidades e agências militares do Norte Global. Mas, olhando com mais cuidado, descobrimos uma divisão profunda do trabalho que irriga o Sul Global por meio de plataformas de crowdsourcing usadas para editar e validar dados.19 A parábola do conjunto de dados ImageNet exemplifica os problemas de muitos conjuntos de dados de IA. O ImageNet é um conjunto de dados de treinamento para Deep Learning [Aprendizagem profunda] que se tornou a referência de facto para algoritmos de reconhecimento de imagem: deveras, a revolução da Deep Learning começou em 2012 quando Alex Krizhevsky, Ilya Sutskever e Geoffrey Hinton venceram o desafio anual do ImageNet com a rede neural convolucional [Convolutional Neural Network] AlexNet.20 O ImageNet foi iniciado pela cientista da computação Fei-Fei Li em 2006.21 A Fei-Fei Li tinha três intuições para criar um conjunto de dados confiável para o reconhecimento de imagens. Primeiro, faça o download de milhões de imagens gratuitas de serviços web, como Flickr e Google. Segundo, adote a taxonomia computacional WordNet para rótulos de imagens.22 Terceiro, terceirize o trabalho de rotular milhões de imagens por meio da plataforma de crowdsourcing Amazon Mechanical Turk. No final do dia (e da linha de montagem), trabalhadores anônimos de todo o planeta recebiam poucos centavos por tarefa para rotular centenas de fotos por minuto, de acordo com a taxonomia do WordNet: tal trabalho resultou na engenharia de uma construção cultural controversa. Os estudiosos da IA, Kate Crawford e o artista Trevor Paglen investigaram e divulgaram a sedimentação de categorias racistas e sexistas na taxonomia ImageNet: veja a legitimação da categoria “pessoa fracassada, perdida, iniciante e mal-sucedida” para cem fotos arbitrárias de pessoas.23
O voraz extrativismo de dados da IA causou uma reação [backlash] imprevisível à cultura digital: no início dos anos 2000, Lawrence Lessig não podia prever que o grande repositório de imagens online creditadas pelas licenças Creative Commons se tornaria uma década mais tarde um recurso não regulamentado para tecnologias de vigilância por reconhecimento facial. De maneira semelhante, os dados pessoais seguem sendo continuamente incorporados sem transparência aos conjuntos de dados privatizados para aprendizado de máquina. Em 2019, o artista e pesquisador de IA Adam Harvey divulgou pela primeira vez o uso não consensual de fotos pessoais em conjuntos de dados de treinamento para reconhecimento facial. A divulgação de Harvey fez com que a Universidade de Stanford, a Universidade de Duke e a Microsoft retirassem seus conjuntos de dados em meio a um grande escândalo de violação de privacidade.24 Os conjuntos de dados de treinamento on-line desencadeiam questões de soberania de dados e direitos civis que as instituições tradicionais demoram a combater (consulte o Regulamento Geral sobre Proteção de Dados da União Européia).25 Se 2012 foi o ano em que a revolução da Deep Learning começou, 2019 foi o ano em que suas fontes foram descobertas vulneráveis e corrompidas. 
Padrões combinatórios e Kufic scripts, pergaminho de Topkapi, Irã, 1500 d.C.
A necessidade de desmistificar a IA (pelo menos do ponto de vista técnico) também é entendida no mundo corporativo. O chefe da IA do Facebook e padrinho das redes neurais convolucionais Yann LeCun reitera que os atuais sistemas de IA não são versões sofisticadas de cognição, mas sim de percepção. Da mesma forma, o diagrama Nooscope expõe o esqueleto da caixa preta da IA e mostra que a IA não é um autômato pensante, mas um algoritmo que executa reconhecimento de padrões. A noção de reconhecimento de padrões contém questões que precisam ser elaboradas. A propósito, o que é um padrão? Um padrão é exclusivamente uma entidade visual? O que significa ler comportamentos sociais como padrões? O reconhecimento de padrões é uma definição exaustiva de inteligência? Muito provavelmente, não. Para esclarecer essas questões, seria bom realizar uma breve arqueologia da IA.
A máquina arquetípica para reconhecimento de padrões é a Perceptron de Frank Rosenblatt. Inventada em 1957 no Laboratório Aeronáutico de Cornell, em Buffalo/Nova York, seu nome é uma abreviação de “Percebendo e Reconhecendo o Autômato”.26 Dada uma matriz visual de fotorreceptores com 20 x 20, a Perceptron pode aprender a reconhecer letras simples. Um padrão visual é registrado como uma impressão em uma rede de neurônios artificiais que são acionados em conjunto com a repetição de imagens semelhantes e ativando um único neurônio de output. O neurônio de output dispara 1 = verdadeiro, se uma determinada imagem for reconhecida, ou 0 = falso, se uma determinada imagem não for reconhecida.
A automação da percepção, como uma montagem visual de pixels ao longo de uma linha de montagem computacional, estava originalmente implícita no conceito de redes neurais artificiais de McCulloch e Pitt.27 Depois que o algoritmo para reconhecimento visual de padrões sobreviveu ao “inverno da IA” e se mostrou eficiente no final dos anos 2000, foi aplicado também a conjuntos de dados não visuais, inaugurando propriamente a era do Deep Learning (a aplicação de técnicas de reconhecimento de padrões a todos os tipos de dados, não apenas visuais). Hoje, no caso de carros autônomos, os padrões que precisam ser reconhecidos são objetos nos cenários das estradas. No caso da tradução automática, os padrões que precisam ser reconhecidos são as sequências de palavras mais comuns nos textos bilíngues. Independentemente de sua complexidade, da perspectiva numérica do aprendizado de máquina, noções como imagem, movimento, forma, estilo e decisão ética podem ser descritas como distribuições estatísticas de padrão. Nesse sentido, o reconhecimento de padrões se tornou verdadeiramente uma nova técnica cultural usada em vários campos. Por motivos de explicação, o Nooscópio é descrito como uma máquina que opera em três modalidades: treinamento, classificação e previsão. Em termos mais intuitivos, essas modalidades podem ser chamadas: extração de padrões, reconhecimento de padrões e geração de padrões.
O Perceptron de Rosenblatt foi o primeiro algoritmo que abriu o caminho para o aprendizado de máquina no sentido contemporâneo. Numa época em que a ‘ciência da computação’ ainda não havia sido adotada como definição, o campo foi chamado de ‘geometria computacional’ e especificamente ‘conexionismo’ pelo próprio Rosenblatt. O negócio dessas redes neurais, todavia, era calcular uma inferência estatística. O que uma rede neural calcula não é um padrão exato, mas a distribuição estatística de um padrão. Apenas raspando a superfície do marketing antropomórfico da IA, encontramos outro objeto técnico e cultural que precisa ser examinado: o modelo estatístico. Qual é o modelo estatístico no aprendizado de máquina? Como é calculado? Qual é a relação entre um modelo estatístico e a cognição humana? Essas são questões cruciais a serem esclarecidas. Em termos do trabalho de desmistificação que precisa ser feito (também para dissipar algumas perguntas ingênuas), seria bom reformular a questão banal “Uma máquina pode pensar?” nas questões teoricamente mais sólidas “Um modelo estatístico pode pensar?”, “Um modelo estatístico pode desenvolver uma consciência?”, et cetera.
Os algoritmos da IA são frequentemente evocados como fórmulas alquímicas, capazes de destilar formas de inteligência ‘alienígenas’. Mas o que os algoritmos de aprendizado de máquina realmente fazem? Poucas pessoas, incluindo os seguidores da Inteligência Artificial Geral [Artificial General Intelligence – AGI], se preocupam em fazer essa pergunta. Algoritmo é o nome de um processo, pelo qual uma máquina faz um cálculo. O produto de tais processos de máquina é um modelo estatístico (mais precisamente denominado “modelo estatístico algorítmico”). Na comunidade de desenvolvedores, o termo ‘algoritmo’ é cada vez mais substituído por ‘modelo’. Essa confusão terminológica surge do fato do modelo estatístico não existir separadamente do algoritmo: de alguma forma, o modelo estatístico existe dentro do algoritmo sob a forma de memória distribuída através de seus parâmetros. Pela mesma razão, é essencialmente impossível visualizar um modelo estatístico algorítmico, como é feito com funções matemáticas simples. Ainda assim, o desafio vale a pena.
No aprendizado de máquina, existem muitas arquiteturas algorítmicas: Perceptron simples, rede neural profunda, Support Vector Machine, rede Bayesiana, cadeia de Markov, autoencoder, máquina de Boltzmann, etc. Cada uma dessas arquiteturas tem uma história diferente (muitas vezes enraizada em agências e corporações militares do Norte Global). As redes neurais artificiais começaram como estruturas de computação simples que evoluíram para estruturas complexas que agora são controladas por alguns hiperparâmetros que expressam milhões de parâmetros.28 Por exemplo, redes neurais convolucionais são descritas por um conjunto limitado de hiperparâmetros (número de camadas, número de neurônios por camada, tipo de conexão, comportamento dos neurônios etc.) que projetam uma topologia complexa de milhares de neurônios artificiais com milhões de parâmetros no total. O algoritmo inicia como uma folha em branco e, durante o processo chamado treinamento, ou ‘aprendendo com os dados’, ajusta seus parâmetros até atingir uma boa representação dos dados de input. No reconhecimento de imagens, como já visto, a computação de milhões de parâmetros deve ser resolvida em um output binário simples: 1=verdadeiro, uma determinada imagem é reconhecida; ou 0=falso, uma determinada imagem não é reconhecida.29

Fonte: https://www.asimovinstitute.org/neural-network-zoo
Tentando uma explicação acessível da relação entre algoritmo e modelo, vamos dar uma olhada no complexo algoritmo Inception v3, uma profunda rede neural convolucional para reconhecimento de imagens projetada no Google e treinada no conjunto de dados ImageNet. Diz-se que a v3 tem uma precisão de 78% na identificação do rótulo de uma imagem, mas o desempenho da ‘inteligência da máquina’ nesse caso também pode ser medido pela proporção entre o tamanho dos dados de treinamento e o algoritmo (ou modelo) treinado. O ImageNet contém 14 milhões de imagens com etiquetas associadas que ocupam aproximadamente 150 gigabytes de memória. Por outro lado, o Inception v3, destinado a representar as informações contidas no ImageNet, tem apenas 92 megabytes. A taxa de compressão entre os dados de treinamento e o modelo descreve parcialmente também a taxa de difração de informações. Uma tabela da documentação da Keras compara esses valores (número de parâmetros, profundidade da camada, dimensão do arquivo e precisão) para os principais modelos de reconhecimento de imagem.30 Essa é uma maneira grosseira, mas eficaz, de mostrar a relação entre modelo e dados, para mostrar como a ‘inteligência’ dos algoritmos é medida e avaliada na comunidade de desenvolvedores.
Documentação por modelos individuais
| Modelo | Tamanho | Top-1 Precisão | Top-5 Precisão | Parametros | Profundidade |
| Xception | 88 MB | 0.790 | 0.945 | 22,910,480 | 126 |
| VGG16 | 528 MB | 0.713 | 0.901 | 138,357,544 | 23 |
| VGG19 | 549 MB | 0.713 | 0.900 | 143,667,240 | 26 |
| ResNet50 | 98 MB | 0.749 | 0.921 | 25,636,712 | – |
| ResNet101 | 171 MB | 0.764 | 0.928 | 44,707,176 | – |
| ResNet152 | 232 MB | 0.766 | 0.931 | 60,419,944 | – |
| ResNet50V2 | 98 MB | 0.760 | 0.930 | 25,613,800 | – |
| ResNet101V2 | 171 MB | 0.772 | 0.938 | 44,675,560 | – |
| ResNet152V2 | 232 MB | 0.780 | 0.942 | 60,380,648 | – |
| InceptionV3 | 92 MB | 0.779 | 0.937 | 23,851,784 | 159 |
| InceptionResNetV2 | 215 MB | 0.803 | 0.953 | 55,873,736 | 572 |
| MobileNet | 16 MB | 0.704 | 0.895 | 4,253,864 | 88 |
| MobileNetV2 | 14 MB | 0.713 | 0.901 | 3,538,984 | 88 |
| DenseNet121 | 33 MB | 0.750 | 0.923 | 8,062,504 | 121 |
| DenseNet169 | 57 MB | 0.762 | 0.932 | 14,307,880 | 169 |
| DenseNet201 | 80 MB | 0.773 | 0.936 | 20,242,984 | 201 |
| NASNetMobile | 23 MB | 0.744 | 0.919 | 5,326,716 | – |
| NASNetLarge | 343 MB | 0.825 | 0.960 | 88,949,818 | – |
Fonte: keras.io/applications
Os modelos estatísticos sempre influenciaram a cultura e a política. Eles não surgiram apenas com o aprendizado de máquina: este é apenas uma nova maneira de automatizar a técnica da modelagem estatística. Quando Greta Thunberg adverte ‘Ouça a ciência’, o que ela realmente quer dizer, sendo uma boa aluna de matemática, é ‘Ouça os modelos estatísticos da ciência climática’. Sem modelos estatísticos, sem ciência climática – e sem ciência climática, sem ativismo climático. A ciência do clima é realmente um bom exemplo para começar, a fim de entender modelos estatísticos. O aquecimento global foi calculado coletando primeiro um vasto conjunto de dados de temperaturas da superfície da Terra todos os dias do ano, e segundo, aplicando um modelo matemático que traça a curva das variações de temperatura no passado e projeta o mesmo padrão no futuro.31 Modelos climáticos são artefatos históricos que são testados e debatidos na comunidade científica, e hoje, também para além dela.32 Os modelos de aprendizado de máquina, pelo contrário, são opacos e inacessíveis ao debate da comunidade. Dado o grau de criação de mitos e viés social em torno de suas construções matemáticas, a IA realmente inaugurou a era da ficção científica estatística. Nooscópio é o projetor deste grande cinema estatístico.
“Todos os modelos estão errados, mas alguns são úteis” – o ditado canônico do estatístico britânico George Box há muito encapsula as limitações lógicas da estatística e do aprendizado de máquina.33 Essa máxima, no entanto, é frequentemente usada para legitimar o viés da IA corporativa e estatal. Os cientistas da computação argumentam que a cognição humana reflete a capacidade de abstrair e de se aproximar de padrões. Então, qual é o problema das máquinas tambem serem formas aproximadas, e fazerem o mesmo? Dentro desse argumento, é repetido retoricamente que “o mapa não é o território”. Isso parece razoável. Mas o que deve ser contestado é que a IA é um mapa fortemente comprimido e distorcido do território e que esse mapa, como muitas formas de automação, não está aberto à negociação da comunidade. AI é um mapa do território sem acesso e consentimento da comunidade.34
Como o aprendizado de máquina traça um mapa estatístico do mundo? Vamos encarar o caso específico do reconhecimento de imagens (a forma básica do trabalho de percepção, que foi codificado e automatizado como reconhecimento de padrões).35 Dada uma imagem a ser classificada, o algoritmo detecta as bordas de um objeto como a distribuição estatística de pixels escuros cercados por pixels claros (um padrão visual típico). O algoritmo não sabe o que é uma imagem, não percebe uma imagem como a cognição humana, apenas calcula pixels, valores numéricos de brilho e proximidade. O algoritmo é programado para registrar apenas a borda escura de um perfil (que se ajusta no padrão desejado) e não, exatamente, todos os pixels da imagem (o que resultaria em um superajuste e na repetição de todo o campo visual). Diz-se que um modelo estatístico é treinado com sucesso quando pode ajustar [fit] elegantemente apenas os padrões importantes dos dados de treinamento e aplicar esses padrões também aos novos dados “em estado selvagem”. Se um modelo aprende muito bem os dados de treinamento, ele reconhece apenas correspondências exatas dos padrões originais e ignorará aqueles com semelhanças próximas, “em estado selvagem”. Neste caso, o modelo é superajustado [overfitting], porque aprendeu meticulosamente tudo (incluindo os ruídos) e não é capaz de distinguir um padrão de seu background. Por outro lado, o modelo é subajustado [underfitting] quando não for capaz de detectar padrões significativos a partir dos dados de treinamento. As noções de superajuste, ajuste e subajuste de dados podem ser visualizadas em um plano cartesiano.

O desafio de proteger a precisão do aprendizado de máquina está na calibração do equilíbrio entre o subajuste e o superajusta dos dados, o que é difícil de executar devido a diferentes vieses da máquina. Aprendizado de máquina é um termo que, tal como “IA”, antropomorfiza uma parte da tecnologia: o aprendizado de máquina não aprende nada no sentido apropriado da palavra, como um humano; o aprendizado de máquina simplesmente mapeia uma distribuição estatística de valores numéricos e desenha uma função matemática que, esperançosamente, se aproxima da compreensão humana. Dito isto, o aprendizado de máquina pode, por esse motivo, lançar uma nova luz sobre as maneiras pelas quais os seres humanos compreendem.
O modelo estatístico dos algoritmos de aprendizado de máquina também é uma aproximação no sentido de adivinhar as partes ausentes do gráfico de dados: por meio de interpolação, que é a previsão de um output y dentro do intervalo conhecido do input x no conjunto de dados de treinamento, ou por extrapolação, que é a previsão do output y além dos limites de x, geralmente com altos riscos de imprecisão. Isso é o que “inteligência” significa hoje em inteligência da máquina: extrapolar uma função não linear além dos limites de dados conhecidos. Como Dan McQuillian coloca apropriadamente: “Não há inteligência em inteligência artificial, nem aprender, mesmo que seu nome técnico seja aprendizado de máquina, ela é simplesmente minimização matemática”.36
É importante lembrar que a “inteligência” do aprendizado de máquina não é dirigida por fórmulas exatas de análise matemática, mas por algoritmos de aproximação de força bruta. O formato da função de correlação entre a input x e a output x é calculado algoritmicamente, passo a passo, através de processos mecânicos cansativos de ajuste gradual (como descida do gradiente [gradient descent], por exemplo) que são equivalentes ao cálculo diferencial de Leibniz e Newton. Diz-se que as redes neurais estão entre os algoritmos mais eficientes, porque esses métodos diferenciais podem se aproximar da forma de qualquer função, com camadas suficientes de neurônios e recursos computacionais abundantes.37 A aproximação gradual de força bruta de uma função é o principal recurso da IA de hoje, e somente dessa perspectiva é possível entender suas potencialidades e limitações – particularmente a escalada da sua pegada de carbono (o treinamento de redes neurais profundas requer quantidades exorbitantes de energia devido à descida do gradiente e algoritmos de treinamento que operam com base em ajustes infinitesimais contínuos).38
As noções de ajuste, superajuste, subajuste, interpolação e extrapolação podem ser facilmente visualizadas em duas dimensões, mas os modelos estatísticos geralmente operam em espaços multidimensionais de dados. Antes de serem analisados, os dados são codificados em um espaço vetorial multidimensional [multi-dimensional vector space] que está longe de ser intuitivo. O que é um espaço vetorial e por que é multidimensional? Cardon, Cointet e Mazière descrevem a vetorização dos dados desta maneira:
Uma rede neural requer que os inputs da calculadora assumam a forma de um vetor. Portanto, o mundo deve ser codificado antecipadamente na forma de uma representação vetorial puramente digital. Enquanto certos objetos, como imagens, são naturalmente divididos em vetores, outros objetos precisam ser ´incorporados´ dentro de um espaço vetorial antes que seja possível calculá-los ou classificá-los com redes neurais. Este é o caso do texto, que é o exemplo prototípico. Para inserir uma palavra em uma rede neural, a técnica Word2vec a “incorpora” em um espaço vetorial que mede sua distância de outras palavras no corpus. Assim, as palavras herdam uma posição dentro de um espaço com várias centenas de dimensões. A vantagem de tal representação reside nas inúmeras operações oferecidas por essa transformação. Dois termos cujas posições inferidas estão próximas umas das outras neste espaço são semelhantes semanticamente; diz-se que essas representações estão distribuídas: o vetor do conceito ‘apartamento’ [-0,2, 0,3, -4,2, 5,1 …] será semelhante ao de ‘casa’ [-0,2, 0,3, -4,0, 5,1. ..] (…) Enquanto o processamento de linguagem natural foi pioneiro na “incorporação” de palavras em um espaço vetorial, hoje estamos testemunhando uma generalização do processo de incorporação que se estende progressivamente a todos os campos de aplicativos: graph2vec, textos com paragraph2vec, filmes com movie2vec, significados das palavras com sens2vec, estruturas moleculares com mol2vec, etc. Segundo Yann LeCun, o objetivo dos projetistas de máquinas conexionistas é colocar o mundo em um vetor (world2vec).39
O espaço vetorial multidimensional é outra razão pela qual a lógica do aprendizado de máquina é difícil de compreender. O espaço vetorial é outra técnica cultural nova, com a qual vale a pena se familiarizar. O campo das Humanidades Digitais, em particular, tem abordado a técnica de vetorização através da qual nosso conhecimento coletivo é invisivelmente renderizado e processado. A definição original de William Gibson de ciberespaço profetizou, muito provavelmente, a chegada de um espaço vetorial em vez da realidade virtual: “Uma representação gráfica de dados abstraídos dos bancos de todos os computadores do sistema humano. Complexidade impensável. Linhas de luz variavam no não-espaço da mente, aglomerados [clusters] e constelações de dados. Como as luzes da cidade, recuando.”40

A direita: espaço vetorial de sete palavras em três contextos 41
Deve-se enfatizar, no entanto, que o aprendizado de máquina ainda se assemelha mais a um artesanato do que a matemática exata. A IA ainda é uma história de “hacks and tricks”, em vez de intuições místicas. Por exemplo, um truque de compressão de informações é a redução dimensional, usada para evitar a Maldição da Dimensionalidade, que é o crescimento exponencial da variedade de recursos no espaço vetorial. As dimensões das categorias que mostram baixa variação no espaço vetorial (ou seja, cujos valores flutuam apenas um pouco) são agregadas para reduzir os custos de cálculo. A redução dimensional pode ser usada para agrupar significados de palavras (como no modelo word2vec), mas também pode levar à redução categorial, que pode ter um impacto na representação da diversidade social. A redução dimensional pode reduzir as taxonomias e introduzir viés, normalizando ainda mais a diversidade mundial e obliterando identidades únicas.42

A maioria das aplicações contemporâneas do aprendizado de máquina pode ser descritas de acordo com duas modalidades a de classificação e a de previsão, que descrevem os contornos de uma nova sociedade de controle e governança estatística. A classificação é conhecida como reconhecimento de padrões, enquanto a previsão pode ser definida também como geração de padrões. Um novo padrão é reconhecido ou gerado ao interrogar o núcleo interno do modelo estatístico.
A classificação de aprendizado de máquina geralmente é empregada para reconhecer um sinal, um objeto ou um rosto humano e atribuir uma categoria correspondente (etiqueta) de acordo com a taxonomia ou convenção cultural. Um arquivo de input (e.g. um tiro na cabeça capturado por uma câmera de vigilância) é executado no modelo para determinar se ele está dentro da sua distribuição estatística ou não. Em caso positivo, é atribuída a etiqueta de output correspondente. Desde os tempos da Perceptron, a classificação tem sido a aplicação originária das redes neurais: com a Deep Learning, essa técnica é onipresente em classificadores de reconhecimento de rosto, que são implantados por forças policiais, assim como por fabricantes de smartphones.
A previsão de aprendizado de máquina é usada para projetar tendências e comportamentos futuros de acordo com os passados, ou seja, para completar uma informação conhecendo apenas uma parte dela. Na modalidade de previsão, uma pequena amostra de dados de input (um iniciador) é usada para prever a parte ausente das informações, seguindo mais uma vez a distribuição estatística do modelo (pode ser a parte de um gráfico numérico orientado para o futuro ou o parte ausente de uma imagem ou arquivo de áudio). Aliás, existem outras modalidades de aprendizado de máquina: a distribuição estatística de um modelo pode ser visualizada dinamicamente por meio de uma técnica chamada exploração espacial latente e, em algumas aplicações recentes de design, também exploração de padrões [pattern exploration].43
A classificação e a previsão de aprendizado de máquina estão se tornando técnicas onipresentes que constituem novas formas de vigilância e governança. Alguns aparelhos, como veículos autônomos e robôs industriais, podem ser uma integração de ambas as modalidades. Um veículo autônomo é treinado para reconhecer diferentes objetos na estrada (pessoas, carros, obstáculos, placas) e prever ações futuras com base em decisões que um motorista humano tomou em circunstâncias semelhantes. Mesmo que reconhecer um obstáculo na estrada pareça um gesto neutro (não é), identificar um ser humano de acordo com categorias de gênero, raça e classe (e na recente pandemia do COVID-19 como doente ou imune), como instituições estatais cada vez mais o fazem, é o gesto de um novo regime disciplinar. A soberba da classificação automatizada causou o renascimento das técnicas lombrosianas reacionárias que se pensava terem sido consignadas à história, técnicas como o Reconhecimento Automático de Gênero (AGR), “um subcampo de reconhecimento facial que visa identificar algoritmicamente o gênero de indivíduos a partir de fotografias ou vídeos”.44

Recentemente, a modalidade generativa de aprendizado de máquina teve um impacto cultural: seu uso na produção de artefatos visuais foi recebido pelos meios de comunicação de massa como a idéia de que a inteligência artificial é “criativa” e pode autonomamente fazer arte. Uma obra de arte que se diz ter sido criada pela IA sempre oculta um operador humano, que aplica a modalidade generativa de uma rede neural treinada em um conjunto de dados específico. Nesta modalidade, a rede neural é executada ao contrário (movendo-se da menor camada de output em direção à maior camada de input) para gerar novos padrões após ser treinada para classificá-los, um processo que geralmente se move da maior camada de input para a menor camada de output. A modalidade generativa, no entanto, tem algumas aplicações úteis: pode ser usada como uma espécie de verificação da realidade para revelar o que o modelo aprendeu, ou seja, para mostrar como o modelo “vê o mundo”. Pode ser aplicado ao modelo de um carro autônomo, por exemplo, para verificar como o cenário da estrada é projetado.
Uma maneira famosa de ilustrar como um modelo estatístico “vê o mundo” é o Google DeepDream. O DeepDream é uma rede neural convolucional baseada no Inception (treinada no conjunto de dados ImageNet mencionado acima) que foi programada por Alexander Mordvintsev para projetar padrões alucinatórios. Mordvintsev teve a idéia de “virar a rede de cabeça para baixo”, ou seja, transformar um classificador em um gerador, usando algum ruído aleatório ou imagens genéricas da paisagem como output.45 Ele descobriu que “redes neurais treinadas para discriminar entre diferentes tipos de imagens também possuem bastante da informação necessária para gerar imagens”. Nos primeiros experimentos do DeepDream, penas de pássaros e olhos de cães começaram a surgir em toda parte, à medida que as raças de cães e as espécies de pássaros são amplamente super-representadas no ImageNet. Também foi descoberto que a categoria ‘haltere’ era aprendida com um braço humano surreal sempre ligado a ele. Prova de que muitas outras categorias do ImageNet são deturpadas.
As duas principais modalidades de classificação e geração podem ser montadas em outras arquiteturas, como nas Redes Adversárias Generativas (GANs). Na arquitetura GAN, uma rede neural com o papel de discriminador (um classificador tradicional) precisa reconhecer uma imagem produzida por uma rede neural com o papel de gerador, em um loop de reforço que treina os dois modelos estatísticos simultaneamente. Para algumas propriedades convergentes de seus respectivos modelos estatísticos, as GANs se mostraram muito boas em gerar imagens altamente realistas. Essa habilidade provocou seu abuso na fabricação de ‘falsificações profundas’ [deep fakes]46. Em relação aos regimes da verdade, uma aplicação controversa semelhante é o uso de GANs para gerar dados sintéticos em pesquisas sobre câncer, nas quais redes neurais treinadas em conjuntos de dados desequilibrados de tecidos cancerígenos começaram a alucinar o câncer onde não havia.47 Nesse caso, “em vez de descobrir coisas, estamos inventando coisas”, observa Fabian Offert, “o espaço da descoberta é idêntico ao espaço de conhecimento que a GAN já tinha.(…) Enquanto nós pensamos que estamos vendo através da GAN – olhando para algo com a ajuda de uma GAN – estamos na verdade vendo dentro de uma GAN. A visão da GAN não é realidade aumentada, é realidade virtual. GANs obscurecem a descoberta e a invenção”.48 A simulação GAN de câncer no cérebro é um exemplo trágico de alucinação científica movido a IA.

Joseph Paul Cohen, Margaux Luck and Sina Honari. ‘Distribution Matching Losses Can Hallucinate Features in Medical Image Translation’, 2018. Cortesia dos autores.
O poder normativo da IA no século XXI tem de ser analisada nestes termos epistemológicos: o que significa enquadrar conhecimento coletivo como padrões, e o que significa desenhar espaços vetoriais e distribuições estatísticas de comportamentos sociais? Segundo Foucault, no início da França moderna, o poder estatístico já era usado para medir normas sociais, discriminando comportamento normal e anormal.49 A IA amplia facilmente o “poder da normalização” das instituições modernas, como a burocracia, a medicina e a estatística (originalmente, o conhecimento numérico possuído pelo Estado sobre sua população), que agora passam para as mãos das corporações de IA. A norma institucional tornou-se computacional: a classificação do sujeito, de corpos e comportamentos parece não ser mais um assunto para registros públicos, mas para algoritmos e centro de dados.50 “A racionalidade centrada nos dados”, concluiu Paula Duarte, “deve ser entendida como uma expressão da colonialidade do poder.”51
Uma lacuna, um atrito, um conflito, no entanto, sempre persiste entre os modelos estatísticos da IA e o sujeito humano que deve ser medido e controlado. Essa lacuna lógica entre os modelos estatísticos da IA e a sociedade é geralmente debatida como viés. Foi amplamente demonstrado como o reconhecimento facial deturpa as minorias sociais e como os bairros negros, por exemplo, são ignorados pelo serviço de logística e entrega movido a IA.52 Se as discriminações de gênero, raça e classe são amplificadas pelos algoritmos de IA, isso também faz parte de um problema maior de discriminação e normalização no núcleo lógico do aprendizado de máquina. A limitação lógica e política da IA é a dificuldade da tecnologia no reconhecimento e previsão de um novo evento. Como o aprendizado de máquina lida com uma anomalia verdadeiramente única, um comportamento social incomum, um ato inovador de interrupção? As duas modalidades de aprendizado de máquina exibem uma limitação que não é meramente uma questão de viés.
Um limite lógico da classificação de aprendizado de máquina, ou reconhecimento de padrões, é a incapacidade de reconhecer uma anomalia única que aparece pela primeira vez, como uma nova metáfora na poesia, uma nova piada na conversa cotidiana ou um obstáculo incomum (um pedestre? um saco de plástico?) no cenário da estrada. A não detecção do novo (algo que nunca ‘foi visto’ por um modelo e, portanto, nunca foi classificado antes em uma categoria conhecida) é um problema particularmente perigoso para carros autônomos e que já causou mortes. A previsão de aprendizado de máquina, ou geração de padrões, mostra falhas semelhantes na adivinhação de tendências e comportamentos futuros. Como uma técnica de compressão de informações, o aprendizado de máquina automatiza a ditadura do passado, de taxonomias e padrões comportamentais do passado, sobre o presente. Esse problema pode ser chamado de regeneração do antigo – a aplicação de uma visão espaço-temporal homogênea que restringe a possibilidade de um novo evento histórico.
Curiosamente, no aprendizado de máquina, a definição lógica de um problema de segurança também descreve o limite lógico de seu potencial criativo. Os problemas característicos da previsão do novo estão logicamente relacionados aos que caracterizam a geração do novo, porque a maneira como um algoritmo de aprendizado de máquina prevê uma tendência em um gráfico de tempo é idêntica à maneira como gera um novo trabalho artístico a partir de padrões aprendidos. A pergunta banal “A IA pode ser criativa?” deve ser reformulado em termos técnicos: o aprendizado de máquina é capaz de criar obras que não são imitações do passado? O aprendizado de máquina é capaz de extrapolar além dos limites estilísticos de seus dados de treinamento? A ‘criatividade’ do aprendizado de máquina é limitada à detecção de estilos a partir dos dados de treinamento e, em seguida, à improvisação aleatória dentro desses estilos. Em outras palavras, o aprendizado de máquina pode explorar e improvisar apenas dentro dos limites lógicos definidos pelos dados de treinamento. Para todas essas questões, e seu grau de compressão de informações, seria mais preciso denominar aprendizado de máquina como arte estatística.

Lewis Fry Richardson, Previsão do Tempo por Processo Numérico, Cambridge University Press, 1922.
Outro erro implícito do aprendizado de máquina é que a correlação estatística entre dois fenômenos é frequentemente adotada para explicar a causa de um para o outro. Nas estatísticas, é comumente entendido que a correlação não implica causalidade, o que significa que apenas uma coincidência estatística não é suficiente para demonstrar a causalidade. Um exemplo trágico pode ser encontrado no trabalho do estatístico Frederick Hoffman, que em 1896 publicou um relatório de 330 páginas para companhias de seguros para demonstrar uma correlação racial entre ser um americano negro e ter uma expectativa de vida curta.53 Na mineração superficial de dados, o aprendizado de máquina pode construir qualquer correlação arbitrária que é, então, percebida como real. Em 2008, essa falácia lógica foi orgulhosamente adotada pelo diretor da Wired, Chris Andersen, que declarou o “fim da teoria” porque “o dilúvio de dados torna obsoleto o método científico”.54 Segundo Andersen, ele próprio não especialista em método científico e inferência lógica, a correlação estatística é suficiente para o Google administrar seus negócios de anúncios; portanto, também deve ser bom o suficiente para descobrir automaticamente paradigmas científicos. Até a Judea Pearl, pioneira em redes bayesianas, acredita que o aprendizado de máquina é obcecado por “ajuste de curvas”, registrando correlações sem fornecer explicações.55 Tal falácia lógica já se tornou política, se considerarmos que as forças policiais em todo o mundo adotaram algoritmos de policiamento preditivo.56 Segundo Dan McQuillan, quando o aprendizado de máquina é aplicado à sociedade dessa maneira, ele se transforma em um aparato biopolítico de preempção, que produz subjetividades que podem ser posteriormente criminalizadas.57 Por fim, o aprendizado de máquina obcecado por “ajuste de curvas” impõe uma cultura estatística e substitui a episteme tradicional de causalidade (e responsabilidade [accountability] política) por uma de correlações cegamente conduzidas pela automação da tomada de decisão.
Até agora, as difrações e alucinações estatísticas do aprendizado de máquina foram seguidas passo a passo através das múltiplas lentes do Nooscópio. Nesse ponto, a orientação do instrumento precisa ser revertida: as teorias científicas, tanto quanto os dispositivos computacionais, tendem a consolidar uma perspectiva abstrata – a “visão científica do lugar nenhum”, que geralmente é apenas o ponto de vista do poder. O estudo obsessivo da IA pode levar o estudioso a um abismo da computação e a ilusão de que a forma técnica ilumina a social. Como Paola Ricaurte observa: “O extrativismo de dados assume que tudo é uma fonte de dados”.58 Como nos emancipar de uma visão do mundo centrada em dados? É hora de perceber que não é o modelo estatístico que constrói o sujeito, mas o sujeito que estrutura o modelo estatístico. Os estudos internalistas e externalistas da IA precisam embaçar: as subjetividades fazem a matemática do controle a partir de dentro, não de fora. Seguindo o que Guattari disse sobre as máquinas em geral, a inteligência das máquinas também é constituída de “formas hiper-desenvolvidas e hiper-concentradas de certos aspectos da subjetividade humana”.59
Em vez de estudar apenas como a tecnologia funciona, a investigação crítica estuda também como ela quebra, como os sujeitos se rebelam contra seu controle normativo e os trabalhadores sabotam suas engrenagens. Nesse sentido, uma maneira de soar os limites da IA é observar as práticas de hackers. O hacking é um método importante de produção de conhecimento, uma investigação epistêmica crucial na obscuridade da IA.60 Os sistemas de aprendizagem profunda para reconhecimento facial desencadearam, por exemplo, formas de ativismo de contra-vigilância. Através de técnicas de ofuscação facial, os seres humanos decidiram tornar-se ininteligíveis à inteligência artificial: isto é, tornarem-se, eles próprios, caixas pretas. As técnicas tradicionais de ofuscação contra a vigilância adquirem imediatamente uma dimensão matemática na era do aprendizado de máquina. Por exemplo, o artista e pesquisador de IA Adam Harvey inventou um tecido de camuflagem chamado HyperFace que engana os algoritmos de visão de computador para ver vários rostos humanos onde não há nenhum.61 O trabalho de Harvey provoca a pergunta: o que constitui uma face para um olho humano, por um lado, e para um algoritmo de visão computacional, por outro? As falhas neurais do HyperFace exploram essa lacuna cognitiva e revelam qual é a aparência de um rosto humano para uma máquina. Essa lacuna entre a percepção humana e da máquina ajuda a introduzir o crescente campo de ataques adversariais.

Adam Harvey, padrão HyperFace, 2016
Os ataques adversariais[2] exploram pontos cegos e regiões fracas no modelo estatístico de uma rede neural, geralmente para enganar um classificador e fazê-lo perceber algo que não existe. No reconhecimento de objetos, um exemplo adversarial pode ser uma imagem manipulada de uma tartaruga, que parece inócua para o olho humano, mas é classificada erroneamente por uma rede neural como um rifle.62 Exemplos adversariais podem ser percebidos como objetos 3D e até adesivos para sinais de trânsito que podem desencaminhar carros autônomos (que podem ler um limite de velocidade de 120 km/h onde na verdade é de 50 km/h).63 Exemplos adversariais são projetados sabendo o que uma máquina nunca viu antes. Esse efeito é obtido também pela engenharia reversa do modelo estatístico ou poluindo o conjunto de dados de treinamento. Nesse último sentido, a técnica de envenenamento de dados tem como alvo o conjunto de dados de treinamento e apresenta dados medicados. Ao fazer isso, altera a precisão do modelo estatístico e cria uma porta dos fundos que pode eventualmente ser explorada por um ataque adversarial.64
O ataque adversarial parece apontar para uma vulnerabilidade matemática comum a todos os modelos de aprendizado de máquina: “Um aspecto intrigante dos exemplos adversariais é que um exemplo gerado para um modelo é frequentemente classificado erroneamente por outros modelos, mesmo quando eles têm arquiteturas diferentes ou foram treinados em conjuntos de treinamento desconexos.”65 Ataques adversariais nos lembram a discrepância entre a percepção humana e da máquina, e que o limite lógico do aprendizado de máquina também é político. O limite lógico e ontológico do aprendizado de máquina é o sujeito indisciplinado ou evento anômalo que escapa à classificação e ao controle. O sujeito do controle algorítmico contra-ataca. Ataques adversariais são uma maneira de sabotar a linha de montagem do aprendizado de máquina, inventando um obstáculo virtual que pode deixar o aparelho de controle em desacordo. Um exemplo adversarial é a sabotagem na era da IA.
[2] N.T – Optamos por traduzir “adversarial” por adversarial e adversariais com vista ao uso corrente no campo técnico da Inteligência Artificial, vide “Artificial Intelligence: A Modern Approach” (4ºEd., 2020) de Stuart J. Russell.e Peter Norvig.
As naturezas do input e output do aprendizado de máquina devem ser esclarecidas. Os problemas de IA não são apenas sobre viés de informação, mas também sobre trabalho. A IA não é apenas um aparelho de controle, mas também um aparelho produtivo. Como acabamos de mencionar, uma força de trabalho invisível está envolvida em cada etapa de sua linha de montagem (composição do conjunto de dados, supervisão de algoritmo, avaliação de modelo etc.). Pipelines de infinitas tarefas irrigam do Norte Global para o Sul Global; plataformas de trabalhadores da Venezuela, Brasil e Itália, por exemplo, são cruciais para ensinar os carros autônomos alemães a “como ver”.66 Contra a idéia de inteligência alienígena no trabalho, deve-se enfatizar que, em todo o processo de computação da IA o trabalhador humano nunca saiu do circuito, ou, com mais precisão, nunca saiu da linha de montagem. Mary Gray e Siddharth Suri cunharam o termo ‘trabalho fantasma‘ para o trabalho invisível que faz a IA parecer artificialmente autônoma.
Além de algumas decisões básicas, a inteligência artificial de hoje não pode funcionar sem humanos no circuito. Seja na entrega de um feed de notícias relevante ou na execução de um pedido complicado de pizza, quando a inteligência artificial (IA) tropeça ou não consegue terminar o trabalho, milhares de empresas chamam as pessoas para concluir o projeto silenciosamente. Essa nova linha de montagem digital agrega o input coletivo de trabalhadores distribuídos, envia peças de projetos em vez de produtos e opera em diversos setores econômicos em todos os momentos do dia e da noite.
Automação é um mito porque as máquinas, incluindo a IA, pedem constantemente ajuda humana, alguns autores sugeriram substituir ‘automação’ pelo termo mais preciso heteromação.67 Heteromação significa que a narrativa familiar da IA como perpetuum mobile só é possível graças a um exército de reserva de trabalhadores.
No entanto, existe uma maneira mais profunda pela qual o trabalho constitui a IA. A fonte de informações do aprendizado de máquina (qualquer que seja o nome: dados de input, dados de treinamento ou apenas dados) é sempre uma representação de habilidades, atividades e comportamentos humanos, da produção social em geral. Todos os conjuntos de dados de treinamento são, implicitamente, um diagrama da divisão do trabalho humano que a IA precisa analisar e automatizar. Os conjuntos de dados para reconhecimento de imagem, por exemplo, registram o trabalho visual que os motoristas, guardas e supervisores geralmente executam durante suas tarefas. Até conjuntos de dados científicos dependem de trabalho científico, planejamento de experimentos, organização de laboratórios e observação analítica.68 Em resumo, a origem da inteligência das máquinas é a divisão do trabalho e seu principal objetivo é a automação do trabalho .
Os historiadores da computação já salientaram os primeiros passos da inteligência de máquina no projeto do século XIX de mecanizar a divisão do trabalho mental, especificamente a tarefa de cálculo a mão.69 O empreendimento da computação desde então tem sido uma combinação de vigilância e disciplina do trabalho, do cálculo ótimo de mais-valia e do planejamento de comportamentos coletivos.70 A computação foi estabelecida por, e ainda segue assim impondo, um regime de visibilidade e inteligibilidade, não apenas de raciocínio lógico. A genealogia da IA como um aparato de poder é confirmada hoje por seu amplo emprego em tecnologias de identificação e predição, mas a principal anomalia que sempre precisa ser computada é a desorganização do trabalho.
Como tecnologia de automação, a IA terá um tremendo impacto no mercado de trabalho. Se a Deep learning tiver uma taxa de erro de 1% no reconhecimento de imagens, por exemplo, significa que aproximadamente 99% do trabalho de rotina baseado em tarefas visuais (por exemplo, segurança aeroportuária) pode ser potencialmente substituído (restrições legais e oposição sindical permitindo). O impacto da IA no trabalho é bem descrito (da perspectiva dos trabalhadores, finalmente) em um documento do European Trade Union Institute, que destaca as “sete dimensões essenciais que a futura regulamentação deve abordar para proteger os trabalhadores”: 1) salvaguardar a privacidade dos trabalhadores e proteção de dados; 2) abordar o problema da vigilância, rastreamento e monitoramento; 3) tornar transparente o objetivo dos algoritmos de IA; 4) garantir o exercício do ‘direito à explicação’ em relação às decisões tomadas por algoritmos ou modelos de aprendizado de máquina; 5) preservar a segurança e a proteção dos trabalhadores nas interações homem-máquina; 6) aumentar a autonomia dos trabalhadores nas interações homem-máquina; 7) permitir que os trabalhadores se tornem alfabetizados em IA.”71
Por fim, o Nooscópio se manifesta por uma nova “Questão das máquinas” na era da IA. A Questão das máquinas foi um debate provocado na Inglaterra durante a revolução industrial, quando a resposta ao emprego de máquinas e o subsequente desemprego tecnológico dos trabalhadores foi uma campanha social para mais educação sobre máquinas, que assumiu a forma do Movimento do Instituto de Mecânica.72 Hoje, é necessária uma Questão das Máquinas Inteligentes para desenvolver mais inteligência coletiva sobre ‘inteligência de máquina’, mais educação pública em vez de ‘máquinas aprendizes’ e seu regime de extrativismo do conhecimento (o que reforça antigas rotas coloniais, basta olharmos o mapa da rede das plataformas de crowdsourcing hoje). Também no Norte Global, essa relação colonial entre a IA corporativa e a produção de conhecimento como um bem comum deve ser destacada. O objetivo do Nooscópio é expor a sala oculta da corporação Mechanical Turk e iluminar o trabalho invisível do conhecimento que faz a inteligência da máquina parecer ideologicamente viva.